Tired of waiting around for Google to index your fresh content? To be of assistance, ensure that your pages can be crawled. But how long does it take for Google to index a new website?
Find out why it’s so challenging to predict how long Google indexing might take and what you can do to make it go faster.
Indexing is the process of taking information from your website, putting it into categories, and putting it into a database. All of the information you may locate with Google Search comes from this database, known as Google indexing.
No matter how closely they match a particular query, pages that aren’t in the index won’t show up in search results.
For the moment, assume that you’ve just added a new page to your blog. You write about a hot topic in your new post in the hopes that it will attract a lot of new readers.
Before you can see how well a page performs on Google Search, it must be indexed.
So, how long does this process actually take? And at what point should you start to fear that your site may be experiencing technical issues because of the lack of indexing?
Let’s look into it!
How long does it take for Google to index a new website: Experts’ Predictions
Google indexing takes up more than 100 million gigabytes of memory and has hundreds of billions of online pages in it.
Furthermore, Google does not place a cap on the number of pages that can be indexed on a website. Pages often don’t have to fight for indexing, even if some pages may have precedence in the indexing queue.
This massive database ought to have space for one more tiny page, right? You don’t have to be concerned about your blog post. You might, regrettably, have to.
Google acknowledges that not every page that its crawlers process will be indexed.
In January 2021, John Mueller, the Google Search Advocate, went into more detail on the subject and revealed that it’s rather common for Google to not index every page of a big website.
He explained that it’s hard for Google to find a good balance between wanting to index as much content as possible and figuring out if it would be useful to people who use search engines.
Because of this, Google often decides on purpose not to index a certain piece of content.
Google doesn’t index low-quality, duplicate, or unpopular pages. The best way to keep spam from showing up in search results is to not index it.
However, as long as you continue to make your blog entries informative and helpful, they will continue to get indexed, right?
The solution is intricate.
16% of useful, indexable pages on popular websites aren’t indexed, according to Onely’s Tomek Rudzki.
What Occurs Prior To Your Page Being Google Indexed?
Since indexing requires time, one may wonder how that time is spent.
How is the content on your website classified and indexed by Google?
Let’s talk about the activities that must take place before the indexing.
Discovery of Content
Let’s return to the scenario where you published a new blog posting. In order to begin indexing this page, Googlebot must first find its URL.
It may occur by:
- utilizing the internal connections you supplied on other blog pages.
- utilizing external links produced by readers of your new content who found them valuable.
- reading an XML sitemap that you’ve submitted to Google Search Console.
- Given that the page has been located, Google is aware of both its existence and URL.
Crawling
“Crawling” is the process of going to a URL and getting the information on the page.
The Googlebot gathers data about a page’s primary subject, the files it contains, the keywords that appear on it, and other details as it crawls.
The crawler finds links on a website, follows them to the next page, and repeats the process.
It’s crucial to keep in mind that Googlebot abides by the guidelines established by robots.txt, which prevents it from crawling any pages that have been forbidden by the instructions you provide there. So, this is how long Google takes to crawl.
Rendering
Screenshot from Google Search Console, September 2022, rendering in GSCS
Rendering is required in order for Googlebot to comprehend not only the pictures, sounds, and videos but also the JavaScript content on the page.
These files have always presented Google with more of a challenge than HTML.
Martin Splitt, a developer advocate for Google, compared rendering to preparing food.
This metaphor compares the first HTML file of a website, which has links to the rest of the site, to a recipe. To view it in your browser, simply press the F12 key on your keyboard.
CSS, JavaScript, photos, and videos are needed to finish a website’s look.
At this point, you work with rendered HTML, also called the Document Object Model.
Martin added that because JavaScript functions as a recipe inside a recipe, running it is the very first rendering stage.
Googlebot used to only index the first HTML version of a page and save the JavaScript rendering for later because the process was expensive and took a long time.
Within the search engine optimization (SEO) community, this phenomenon was referred to as “the two waves of indexing.”
But it appears that the two waves are no longer required.
According to Mueller and Splitt, almost every new website automatically goes through the rendering stage.
Making crawling, rendering, and indexing happen more often is one of Google’s objectives.
Can You Speed Up the Indexation of Your Page?
Google won’t index your new page if you try to force it.
You have no influence over how quickly this occurs. You may, however, make your sites more crawlable and discoverable by optimizing them. So, how long does it take for Google to index a new website?
What you must do is as follows:
Verify Page Indexability
Keep in mind these two guidelines to keep your pages indexable:
- Avoid using robots.txt or the no-index directive to block them.
- Use a canonical tag to identify the version of a piece of content that should be used as the standard.
A file called Robots.txt contains guidelines for robots visiting your website.
It restricts crawlers from certain sites or directories. Just use the prohibited directive.
For instance, your robots.txt file should have the following instructions if you don’t want robots to browse the sites and files in the “example” folder:
User-agent: *
Disallow: /example/
By accident, it’s possible to occasionally prevent Googlebot from indexing important pages.
You should absolutely look at your robots.txt if you are worried that technical issues are preventing search engines from indexing your content.
Being considerate, Googlebot won’t send any pages to the indexing pipeline that have been requested not to. One way to send such a command is to add a no-index directive to the file:
- X-Robots-tag in the HTTP header response of your page’s URL.
- Meta robots tag in the <head> section of your page.
Make sure that pages that should be indexed don’t contain this directive.
As we previously discussed, Google intends to prevent indexing duplicate content. If it finds two pages that seem to be exact copies of each other, it will probably only index one of them.
The canonical tag was made to avoid confusion and quickly point Googlebot to the URL that the site owner thinks is the original version of the page.
Keep in mind that a page’s source code shouldn’t designate another page as the page that should be in the Google index.
Provide A Sitemap
Every URL on your website that you want to be indexed is listed in a sitemap (up to 50,000).
You can upload it to the Google Search Console to hasten Google’s sitemap discovery.
By giving Googlebot a sitemap, you make it more likely that it will crawl any pages it missed when it was looking at internal links.
Including a sitemap reference in your robots.txt file is a smart idea.
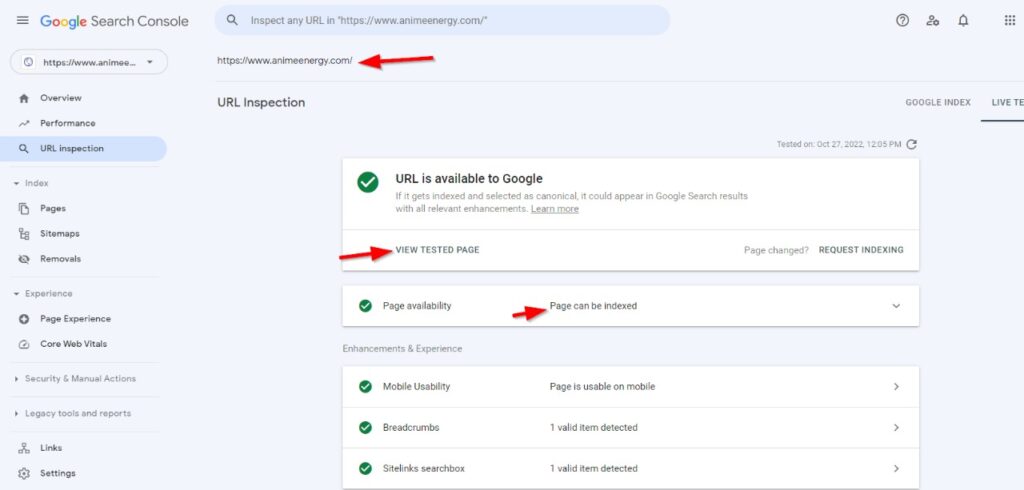
Request That Google Index Revisit Your Pages
Google Search Console screenshot of the inspect tool, September 2022
Using the URL Inspection feature in Google Search, you may ask for a crawl of certain URLs. This won’t ensure indexing and will require some waiting, but it’s another option to make sure Google is aware of your page’s existence.
Use the Google Index API if Applicable
A tool called the Indexing API enables you to inform Google about recently added pages.
This technology allows Google to more effectively schedule the indexing of time-sensitive content.
You can’t use this technology for your blog posts right now because it’s only made for pages with job listings and live videos.
The Indexing API is used by some SEO experts for various types of pages, and while it might be effective in the short term, it is unlikely to be a long-term solution.
Stop Your Website’s Servers From Being Overloaded
Last but not least, make sure that your server has enough bandwidth so that Googlebot doesn’t have to crawl your page more slowly.
Avoid using shared hosting companies, and make sure your server can handle the workload by doing frequent stress tests.
This explains how long does it take for Google to index a new website.